Cache 的基本工作原理
局部性原理
时间局部性:指被访问的某个存储单元在一个较短的时间内很可能还会继续被访问
空间局部性:被访问的某个存储单元临近的单元在一个较短时间内很可能被访问
cache 基本工作原理
cache 是一个小容量的高速缓冲存储器,在 CPU 和主存内部设置 cache
根据局部性原理,CPU访问指令和数据时可以直接从 cache 中读取,而不必到主存内部进行读取,cache 能减少不必要的访问主存,加快读取速度
cache 和主存空间被划分为相等的区域,便于 cache 和主存间交换信息
主存中按照一定的字节划分为一个区域(假定这里是 512 字节),这个区域称为主存块(简称块),而 cache 中存放这样的一个主存块的区域称为 cache 行(简称行)
有了 cache 之后 CPU 的访问过程:
- 先检查 cache 中有没有要访问的信息
- 如果有,直接在 cache 中读写
- 没有,从主存中读写,并且把当前访问的信息复制到 cache 中
在访问的过程中,如果 CPU 需要访问单元所在的主存 cache 中,则称之为 cache 命中,否则称为不命中
那么 CPU 在访问的过程中如何知道 cache 是否命中呢?
cache 行和主存块的映射
想要知道 cache 是否命中,cache 和主存块之间需要有个对应的映射关系
主存块和 cache 行之间主要要三种映射关系:
- 直接映射:每个主存块映射到 cache 固定的行中
- 全相联:每个主存块映射到 cache 的任意行
- 组相联:每个主存块映射到 cache 的固定组的任意行中
直接映射
基本思路是:把主存的每一块映射到固定的 cache 中,也称之为模映射,对应关系如下:
cache 行号 = 主存块号 mod cache行数
假设 cache 有2^c 行,主存块有 2^m 块,主存块大小位 2^b 字节,则 cache 行占 c 位,主存块号占 m 位,块内地址有 b 位,m位的主存块号被分为标记字段和 cache 行号字段
 下面是主存块和 cache 行之间的映射关系图:
下面是主存块和 cache 行之间的映射关系图:
(U3ETFIWM26@0B.jpg)
全相联映射
全相联映射是将主存块装入到 cache 的任意行中,查找过程中,需要比较所有 cache 行的标记,主存地址只有标记和块内地址两个字段
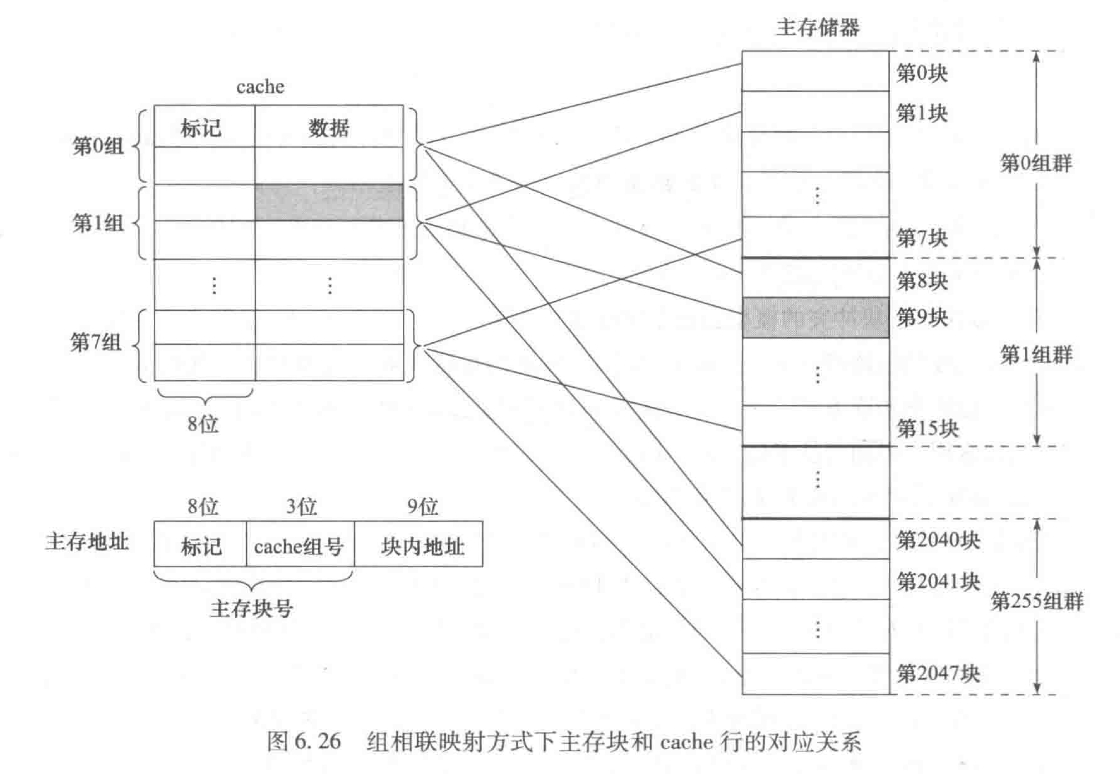
组相联映射
组相联映射将 cache 分成大小相等的组,每个主存块被映射到 cache 固定组的任意一,映射关系如下:
cache 组号 = 主存块号 mod cache 组数
假设 cache 有 2^c 行,分成 2^q 组,每组有 2^(c-q) 行,设 s = c - q,则cache 映射方式称为 2^s 路组相联映射
如果主存块有2^m 块,大小为 2^b 字节,按照字节编制则,块内地址有 b 位,cache 组号有 q 位,标记和 cache 组号共 m 位,标记 t = m - q位
 例子:主存块和 cache 之间按照 2 路组相联映射,块大小512字,cache 数据区容量位 8K 字,主存地址空间为 1M字。问:主存地址如何划分?并说明CPU 对主存单元 01202H 的访问过程
例子:主存块和 cache 之间按照 2 路组相联映射,块大小512字,cache 数据区容量位 8K 字,主存地址空间为 1M字。问:主存地址如何划分?并说明CPU 对主存单元 01202H 的访问过程
解:cache 数据容量为 8K = 2^13 字 = 2^3组 * 2^1 行/组 * 512字/行
主存地址空间为 1M 字 = 2^20 字 = 2^11块 * 512字/块 = 2^8组群 * 2^3块/组群 * 512 字/块
主存地址位数 n为 20,组号位数 q = 3,标记位t = 8 位,块内地址 b = 9 位
 主存地址01202H 二进制为 0000 0001 0010 0000 0010,主存地址划分为:
主存地址01202H 二进制为 0000 0001 0010 0000 0010,主存地址划分为:

访问过程:
- 根据中间3位 001,找到 cache 第一组
- 将标记位 0000 0001 与第一组 cache 中的两行进行比较
- 如果相等并且有效位为 1,则命中,此时将低9位块内地址对应行中取出单元内容送到 CPU 中
- 如果都不相等,或有一个相等但有效位为0,则不命中,此时将01202H单元所在的主存第 0000 0001 001块复制到 cache 第001组中任意一个空闲行中,有效位设置为1,标记设为 0000 0001
cache 中主存块的替换算法
cache 行数比主存块数小,多个主存块可能会映射到同一个 cache 行中,一旦cache 中对应的行满了,需要考虑淘汰掉一个cache 行中的主存块
如果说新的主存块可以放在多个cache 行中,具体需要调出哪一个块,就是淘汰策略问题,主要包括:先进先出(FIFO)、最近最少使用(LRU)、最不经常使用(LFU)和随机替换等
先进先出算法
基本思想是:选择最早装入 cache 的主存块替换掉
最近最少使用算法
基本思路是:选择近期最少使用的主存块被替换掉,这种算法能够正确反映访问的局部性,但是实现起来稍微复杂
最不经常使用算法
基本思路:替换掉 cache 中引用次数最少的块
随机替换算法
从候选的主存块中随机选取一个淘汰
cache 一致性问题
当 CPU 进行写操作时,需要对 cache 中的内容进行更新,此时 cache 和主存需要保持一致
通常两种写操作方式:1)全写法;2)回写法
全写法
全写法(write through):基本做法是,当 CPU 执行写操作时,如写命中,则同时写 cache 和主存,如果没有命中,采用下面两种处理方式
- 写分配法:先在主存块中更新相应的存储单元,然后分配一个 cache 行,将更新后的主存块转入到分配的 cache 行中
- 非写分配法:仅更新主存单元而不转入 cache 行中
回写法
回写法(write back):当 CPU 执行写操作时,若命中 cache,则信息只写入 cache 而不写入主存;如果没有命中,则cache 中分配一行,将主存块调入改 cache 中并更新 cache 中相应单元的内容
当 CPU 执行写操作时,回写法不会更新主存单元,只有当 cache 行踪主存块被替换时,才将主存快内容一次性写回主存
这种做法能够减少写主存的次数,减少写回主存的开销,但是没有同步更新主存块和 cache,可能会由于两者不一致带来潜在隐患